77 KiB
Kubernetes на Orange Pi 5 Plus под управлением Ubuntu 20.04 (на других Orange Pi, Raspberry Pi и других SBC тоже должно работать)
Подготовка
Установим DBus и Avahi (не обязательно)
DBus — система межпроцессного взаимодействия, которая позволяет различным приложениям и службам в системе общаться друг с другом. DBus часто используется для управления службами, взаимодействия с системными демонами и упрощения интеграции приложений.
Avahi — это демон и утилиты для работы с mDNS/DNS-SD (Bonjour) и реализация протокола Zeroconf. Avahi тесно интегрирован с D-Bus и используется для обнаружения устройств и сервисов в локальной сети и предоставляет автоматическое обнаружение устройств и сервисов в локальной сети. Например, Avahi используется для обнаружения сетевых принтеров, файловых серверов и других ресурсов без необходимости ручной настройки. Нам avahi понадобится для обнаружения хостов кластера в локальной сети.
sudo apt update
sudo apt install dbus avahi-daemon avahi-utils
Запускаем эти сервисы:
sudo systemctl start dbus
sudo systemctl start avahi-daemon
А также включаем автозапуск при загрузке:
sudo systemctl enable dbus
sudo systemctl enable avahi-daemon
Возможные проблемы с DBus
При проверке статуса dbus sudo systemctl status dbus, случается, выскакивают предупреждения, типа:
Xxx xx xx:xx:xx _xxx-hostname-xxx_ dbus-daemon[909]: Unknown username "whoopsie" in message bus configuration file
Это связано с тем, что в конфигурационном файле DBus указаны несуществующий пользователь whoopsie. Это системный пользователь, используемый сервисом Whoopsie, отвечающий за отправку отчётов об ошибках на серверы разработчиков (Canonical) в системах Ubuntu. Если whoopsie или его конфигурация установлены, но пользователь отсутствует, возникают такие предупреждения.
Я не возражаю против отправки отчётов об ошибках, тем более, что сервис whoopsie у меня не запущен. :) Так что просто добавлю пользователя whoopsie в систему:
sudo adduser --system --no-create-home --disabled-login whoopsie
Но если внутренний параноик вам шепчет, что это не безопасно, то нужно найти в каких конфигурационных файлах DBus встречается whoopsie grep -r "whoopsie" /etc/dbus-1/ и закомментировать или удалить соответствующие строки.
Также, порадовать своего внутреннего параноика, можно отключить отправку отчётов об ошибках в Ubuntu:
sudo systemctl stop whoopsie
sudo apt-get remove --purge whoopsie
После всех упражнений (добавления пользователя whoopsie или, наоборот истребления его, и отключения сервиса whoopsie) перезагрузим D-Bus:
sudo systemctl restart dbus
Теперь проверкак статуса dbus:
sudo systemctl status dbus
Не должна выдавать предупреждений:
dbus.service - D-Bus System Message Bus
Loaded: loaded (/lib/systemd/system/dbus.service; static)
Active: active (running) since Sat XXXX-XX-XX XX:XX:XX MSK; 1min ago
TriggeredBy: ● dbus.socket
Docs: man:dbus-daemon(1)
Main PID: 8437 (dbus-daemon)
Tasks: 1 (limit: 18675)
Memory: 616.0K
CPU: 112ms
CGroup: /system.slice/dbus.service
└─8437 @dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only
XXX XX XX:XX:XX _xxx-hostname-xxx_ systemd[1]: Started D-Bus System Message Bus.
Возможные проблемы с Avahi
При проверке статуса avahi sudo systemctl status avahi-daemon, случается, выскакивают предупреждения, типа:
Xxx xx xx:xx:xx _xxx-hostname-xxx_ avahi-daemon[2079]: Failed to parse address 'fe80::1%xxxxxxxx', ignoring.
Я не понял как это исправить и почему локальная петля (loopback) для iv6 fe80::1 — проблема. Отключение
обслуживания IPv6 для avahi в конфиге /etc/avahi/avahi-daemon.conf не помогло. Ставил в нем use-ipv6=no,
но предупреждения продолжались. Но, вроде, это не критично, но...
| СООБЩАЙТЕ, ЕСЛИ ЗНАЕТЕ КАК ЭТО ИСПРАВИТЬ! |
Пока я нашел следующее решение (по карйне мере у меня сработало, и сработало только если его проделать после всех
предыдущих пунктов по установке avahi-daemon вручную). Порядок действий напоминает шаманство:
Запускаем конфигуратор Orange Pi:
sudo orangepi-config
Панель orangepi-config на Orange Pi 5 выглядит так:
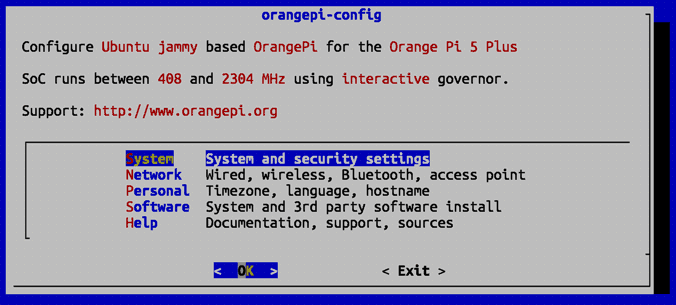
Выбираем пункт 'System: System and security settings' и заходим в панель 'System Settings'. Выбираем в ней пункт 'Avahi: Announce system in the network':
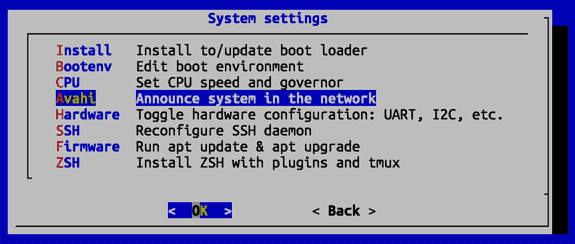
Сервис устанавливается.

Возможно, на панели 'System Setting' вместо пункта 'Avahi: Announce system in the network' будет пункт 'Avahi: Disable system announcement in the network':
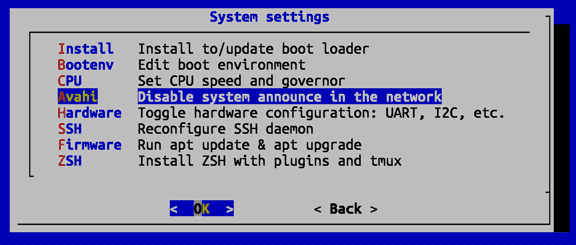
Всё равно выбираем его: сначала отключаем avahi-демон; после возвращаемся в 'System Settings'; повторно выбираем пункт 'Avahi: Announce system in the network' и устанавливаем avahi-демон заново через 'Avahi: Announce system in the network'... Всё как у настоящих системщиков — надо "выйти и зайти".
Покидаем orangepi-config (Back и затем Exit) и перезагружаем Orange Pi:
sudo reboot
После перезагрузки предупреждения о проблемах loopback для iv6 (fe80::1) в avahi должны исчезнуть.
sudo service avahi-daemon status
Все чисто. Магия!
Настройка сети
hostname
Настроить имя хоста (hostname) можно командой hostnamectl. Например, для узла opi5plus-1:
sudo hostnamectl set-hostname opi5plus-1
Или просто отредактировать файл /etc/hostname:
sudo nano /etc/hostname
И внесем в него имя узла (на самом деле заменим, т.к. в файле уже прописано имя хоста). Например, opi5plus-1,
opi5plus-2 и так далее. Сохраняем и закрываем файл.
Изменения вступят в силу после перезагрузки узла. Но чтобы не перезагружать узел, можно применить изменения в /etc/hostname сразу:
sudo service systemd-hostnamed restart
Кстати, чтобы временно изменить hostname, можно использовать команду hostname. Например для узла opi5plus-1:
sudo hostname opi5plus-1
Что бы узнать текущее имя хоста, можно использовать команду hostname:
hostname
ip
Можно настроить статический IP-адрес для каждого узла кластера (об этом будет отдельная заметка). Но можно и оставить и автоматическое получение IP-адреса от DHCP-сервера. Для этого надо на зарезервировать IP-адреса для каждого узла кластера в DHCP-сервере. Резервирование IP-адресов в DHCP-сервере обычно делается по MAC-адресу устройства.
Чтобы узнать MAC- и IP-адреса Orange Pi. На Ubuntu это можно сделать, например, с помощью команды ifconfig.
Увидим что-то вроде этого:
...
...
enP4p65s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.110 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::1e2f:65ff:fe49:3ab0 prefixlen 64 scopeid 0x20<link>
ether 1c:2f:65:49:3a:b0 txqueuelen 1000 (Ethernet)
RX packets 656166 bytes 157816045 (157.8 MB)
RX errors 0 dropped 12472 overruns 0 frame 0
TX packets 44578 bytes 4805687 (4.8 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
...
- MAC-адрес:
ether 1c:2f:65:49:3a:b0 - IP-адрес:
inet 192.168.1.110
И кстати, на Orange Pi 5 Plus есть два сетевых интерфейса: enP4p65s0 и enP3p49s0 (и, если установлен
WiFi-адаптер PCIe, ещё и третий). Так что стоит зарезервировать в DHCP адреса для всех интерфейсов.
DNS
На всякий случай, установим утилиты для работы с DNS (они обычно уже установлены в Ubuntu, но на всякий случай):
sudo apt install dnsutils
В случае с DHCP настройки DNS получены автоматически, при каждой перезагрузке узла конфигурационный файл
/etc/resolv.conf будет перезаписываться. Но если у нас статический IP-адрес, то нам надо настроить /etc/resolv.conf
вручную. В нем указывается DNS-сервер, к которому обращается узел для преобразования доменных имен в IP-адреса,
а так же указывается домен, к которому принадлежит узел и который будет использоваться по умолчанию для преобразования
коротких доменных имен в полные.
sudo nano /etc/resolv.conf
В файле, обычно уже прописаны DNS-сервера. Нам остается только добавить доменное имя. Получим что-то типа вот такого:
# Generated by NetworkManager
nameserver 192.168.1.1
nameserver fe80::1%enP4p65s0
search local
Как видим мы добавили строку search local, где local — это доменное имя которое будет добавляться к коротким,
и таким образом hostname в нашем случае opi5plus-1 будет преобразовываться в opi5plus-1.local. Сохраняем и
закрываем файл.
hosts
Что бы узлы кластера могли общаться между собой по именам, нам надо добавить их в файл /etc/hosts. Откроем его:
sudo nano /etc/hosts
И добавим в него строки вида для каждого узла кластера. Например, для узлов opi5plus-1:
127.0.0.1 localhost
127.0.1.1 opi5plus-1.local opi5plus-1
::1 localhost ip6-localhost ip6-loopback opi5plus-1.local opi5plus-1
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
# УЗЛЫ КЛАСТЕРА (не забудьте заменить ip-адреса и имена узлов)
192.168.1.XX1 opi5 opi5.local
192.168.1.XX2 opi5plus-1 opi5plus-1.local
192.168.1.XX3 opi5plus-2 opi5plus-2.local
192.168.1.XX4 opi5plus-3 opi5plus-3.local
192.168.1.XX5 rpi3b rpi3b.local
Перезагружаем сетевые настройки:
sudo service networking restart
Теперь узлы кластера могут общаться между собой по именам. Можно проверить, например, пингом:
ping opi5plus-3
SSH-авторизация по ключам
Для общения между узлами кластера по SSH без ввода пароля, нам надо настроить авторизацию по ключам. Выпустим по паре ключей (публичный и приватный) на каждом узле кластера. На каждом узле выполним команду:
ssh-keygen -t rsa
В процессе генерации ключей нам предложат указать место для сохранения ключей. По умолчанию они сохраняются в папке
~/.ssh/ (папка .ssh в домашнем каталоге пользователя). Можно оставить по умолчанию, нажав Enter. Так же предложат
указать пароль для ключа. Нужно оставить пустым, нажав Enter. После генерации ключей, в папке ~/.ssh/ появятся два
файла: id_rsa (приватный ключ) и id_rsa.pub (публичный ключ).
Теперь надо обменяться публичными ключами между узлами кластера. Для этого на каждом узле кластера выполним команды,
например для узла opi5plus-1.local (не забываем заменить [user] на имя пользователя):
ssh-copy-id [user]@opi5plus-2.local
ssh-copy-id [user]@opi5plus-3.local
Таким образом, хост opi5plus-1.local отправит свой публичный ключ на хосты opi5plus-2.local и opi5plus-3.local.
С другими узлами кластера поступим аналогично.
При обмене ключами сначала попросят ввести yes для подтверждения подключения к хосту, и предотвращения MITM-атаки
(Man-In-The-Middle — человек посередине). После этого попросят ввести пароль пользователя на удаленном хосте. После
успешного ввода пароля, публичный ключ будет добавлен в файл ~/.ssh/authorized_keys на удаленном хосте. Теперь можно
подключаться к удаленному хосту без ввода пароля.
Проверим, что авторизация по ключам работает. Подключимся к удаленному хосту (например к opi5plus-2.local):
ssh [user]@opi5plus-2.local
Для отключения с удаленного хоста наберем команду logout.
Еще немного подготовительных действий
Настойка времени
Для самого Kubernates не так важно, чтобы время на всех узлах было синхронизировано, но для баз данных, кэшей и других сервисов, работающих на узлах кластера, это может оказаться критичным. Поэтому настроим синхронизацию времени.
Посмотреть текущий часовой пояс можно командой:
timedatectl
Установим на всех узлах один и тот же часовой пояс. Например, для Москвы:
sudo timedatectl set-timezone Europe/Moscow
На Orange Pi 5 настройку часового пояса можно сделать и через sudo orangepi-config (пункт 'System: Timezone').
Также установим NTP (Network Time Protocol) для синхронизации времени. Описание установки и настройки есть в другой заметке.
Следует отметить, что т.к. у Orange Pi 5 Plus есть встроенные часы реального времени (RTC), а NTP-клиент имеет
более высокие накладные расходы, по сравнению с SNTP (Simple Network Time Protocol). Для микрокомпьютеров можно
немного поднастроить NTP. В частности убрать дефолтный список серверов времени и добавить только ближайшие к нам.
Список NTP-серверов можно посмотреть на сайте ntppool.org. Например, для России список
пула в /etc/ntp.conf будет такой (и добавим еще московский сервер...
и не забудьте убрать дефолтные):
pool 0.ru.pool.ntp.org minpoll 9 maxpoll 14
pool 1.ru.pool.ntp.org minpoll 9 maxpoll 14
pool 2.ru.pool.ntp.org minpoll 9 maxpoll 14
pool 3.ru.pool.ntp.org minpoll 9 maxpoll 14
server ntp.msk-ix.ru minpoll 8 maxpoll 12 prefer
Здесь:
pool— Указывает пул серверов времени. Клиент автоматически выбирает серверы из указанного пула и может переключаться между ними для повышения надежности и отказоустойчивости.server— указывает конкретный сервер времени для синхронизации. Если сервер недоступен, NTP-клиент будет пытаться подключиться к нему снова через некоторое время.minpollиmaxpoll— это минимальный и максимальный интервалы обращения к серверу. Значения — это степени двойки. По умолчанию значения равны 6 (64 секунды) и 10 (~17 минут). Но для микрокомпьютеров можно установить побольше. У нас 9 (~8.5 минуты) и 14 (~4.5 часа). На самом деле обращения к серверам времени будут происходить в случайные интервалы времени (jitter), но в пределах указанных значений.prefer-- это приоритетный сервер. Если у нас несколько серверов, то NTP-клиент будет обращаться к приоритетному.
Это позволит уменьшить нагрузку от NTP-клиента и снизить трафик.
Установка необходимых пакетов
В системе уже должны быть установлены пакеты apt-transport-https (для работы с HTTPS-репозиториями) и curl (для
передачи и получения данных с использованием различных протоколов), wget (для загрузки файлов из интернета), gnupg
(для работы с GPG-ключами), sudo (для выполнения команд от имени суперпользователя), iptables (для настройки
фильтрации пакетов), tmux (для работы с несколькими терминалами в одном окне). Проверим их наличие:
sudo apt install apt-transport-https curl wget gnupg sudo iptables tmux
Также установим keepalived (для обеспечения высокой доступности, балансировки нагрузки, мониторинга состояния
серверов и автоматического переключения на резервные серверы в случае сбоя) и haproxy (балансировщик нагрузки и
прокси-сервер для TCP и HTTP приложений, для распределения трафика между серверами и обеспечения высокой доступности).
sudo apt install keepalived haproxy
Модули и параметры ядра
В каждом узле, создадим конфигурационный файл для загрузки необходимых Kubernetes модулей ядра (overlay и
br_netfilter). Для этого создадим конфиг в папке /etc/modules-load.d/. Файл может иметь любое имя с расширением
.conf, для удобства назовем его k8s.conf:
sudo nano /etc/modules-load.d/k8s.conf
В файле пропишем модули:
# Load overlay module (драйвер для работы с файловой системой overlayfs, для объединения
# нескольких файловых систем в одну)
overlay
# Load br_netfilter module (Драйвер для работы с сетевыми мостами и фильтрацией пакетов)
br_netfilter
Сохраняем и закрываем файл и теперь, благодаря конфигу, эти модули ядра будут автоматически загружаться при каждой перезагрузке узла. Но чтобы загрузить сразу и сейчас выполним команды:
sudo modprobe overlay
sudo modprobe br_netfilter
Проверим, что модуль overlay загружен:
lsmod | grep overlay
Увидим что-то вроде:
overlay 126976 0
Цифры 126976 — это размер модуля в байтах и 0 — количество других модулей, которые используют этот модуль.
Проверим для модуля br_netfilter:
`lsmod | grep br_netfilter`
Увидим типа такого:
br_netfilter 28672 0
bridge 266240 1 br_netfilter
Как видим, модуль br_netfilter загружен, и он используется модулем bridge.
Затем создадим конфигурационный файл для ядра Linux в папке /etc/sysctl.d/. В эту папку помещаются файлы с
для настройки параметров ядра Linux. Создадим файл k8s.conf:
sudo nano /etc/sysctl.d/k8s.conf
В файле пропишем параметры:
# Enable IPv6 traffic through iptables on bridges (Разрешаем обработку IPv6-трафика через iptables на сетевых мостах)
net.bridge.bridge-nf-call-ip6tables = 1
# Enable IPv4 traffic through iptables on bridges (Разрешаем обработку IPv4-трафика через iptables на сетевых мостах)
net.bridge.bridge-nf-call-iptables = 1
# Enable IP forwarding (Разрешаем пересылку IP-пакетов для маршрутизации трафика между контейнерами)
net.ipv4.ip_forward = 1
В принципе, первые два параметра уже установлены по умолчанию (посмотреть текущие параметры ядра можно командой
sysctl -a), но на всякий случай все равно укажем их в файле. Сохраняем и закрываем файл. Теперь при перезагрузке
узла эти параметры будут загружаться автоматически. Но чтобы загрузить их сразу исопльзуем команду:
sudo sysctl -f /etc/sysctl.d/k8s.conf
Проверим, что параметры загружены:
sudo sysctl net.bridge.bridge-nf-call-iptables net.bridge.bridge-nf-call-ip6tables net.ipv4.ip_forward
Увидим, что параметры установлены:
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
Отключение swap
Для обеспечения стабильной и предсказуемой работы контейнеров, Kubernetes требует отключения файла подкачки (swap). Это может замедлить работу системы (по этому лучше использовать Orange Pi c большим объемом памяти), но когда включен swap, ядро может перемещать неактивные страницы памяти на диск, что может привести к задержкам и непредсказуемому поведению контейнеров. Отключение swap позволяет Kubernetes более точно управлять ресурсами и гарантировать, что контейнерам будет выделено достаточно памяти.
Проверим, включен ли swap:
sudo swapon --show
Если увидим, что swap включен, например вот так:
NAME TYPE SIZE USED PRIO
/dev/zram0 partition 7.8G 0B 5
Как видим, у нас есть swap-раздел /dev/zram0. Это "электронный диск" в памяти, который используется для
кэширования данных. Отключим его:
sudo swapoff /dev/zram0
Сначала узнать как на самом деле называется служба zram в вашей системе можно командой:
systemctl list-units --type=service | grep zram
Затем отключим эту службу чтобы электронный диск не создавался при каждой загрузке:
sudo systemctl disable orangepi-zram-config.service
И остановим службу:
sudo service orangepi-zram-config stop
И наконец, удалим соответствующие записи из файла /etc/fstab, чтобы предотвратить их автоматическое монтирование при
загрузке системы. Для этого удалим из файла /etc/fstab строку, содержащую /dev/zram0:
sudo sed -i '/zram0/d' /etc/fstab
Теперь проверим, что swap отключен:
sudo swapon --show
Если ничего не выводится, значит swap отключен. Но возможно, даже если swap отключен и его нет в /etc/fstab, он может
был создан и включен с помощью dphys-swapfile. Чтобы исключить swap сперва отключим его:
sudo swapoff -a
Отключим службу dphys-swapfil:
sudo service dphys-swapfile stop
sudo systemctl disable dphys-swapfile
И удалим файл подкачки, если он есть:
sudo rm /var/swap
Установим Docker и Kubernetes
Ключи и репозитории
Для начала на каждом узле нашего будущего кластера надо установить GPG-ключи репозитория Docker и Kubernetes.
Установка GPG-ключей для Docker подробна описана в отдельной инструкции. Для
Kubernetes ключи устанавливаются похожим образом. Скачиваем GPG-ключ в папку /etc/apt/trusted.gpg.d/:
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.30/deb/Release.key | sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/kubernetes-apt-keyring.gpg
Добавляем репозиторий Kubernetes (с указанием этого GPG-ключа и ARM-платформы, ведь у нас Orange Pi 5 Plus на ARM64):
echo 'deb [arch=arm64 signed-by=/etc/apt/trusted.gpg.d/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.30/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
А для старенького Raspberry Pi 3 Model B+ на ARMv7:
echo 'deb [arch=armhf signed-by=/etc/apt/trusted.gpg.d/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.30/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
Готово. Теперь обновим список пакетов:
sudo apt update
Установка Docker и Kubernetes
Наконец, установим Docker и Kubernetes:
sudo apt install docker-ce docker-ce-cli containerd.io docker-compose-plugin kubelet kubeadm kubectl
Где:
docker-ce— это Docker Community Edition (Docker CE) — это бесплатная версия Docker, которая включает в себя Docker Engine, Docker CLI и Docker Compose.containerd.io— это контейнерный менеджер, который управляет жизненным циклом контейнеров.docker-compose-plugin— это плагин для Docker, который позволяет использовать Docker Compose с Kubernetes.kubelet— это агент, который работает на каждом узле кластера и отвечает за запуск контейнеров.kubeadm— это утилита для управления кластером Kubernetes.kubectl— это утилита командной строки для управления кластером Kubernetes.
Установка CRI (Container Runtime Interface
Так же нам надо на каждый узел установить cri-dockerd — демон, который позволяет Kubernetes использовать
Docker в качестве контейнерного рантайма. Начиная с версии 1.20, Kubernetes прекратил прямую поддержку Docker
и для взаимодействия появился cri-dockerd — интерфейс Container Runtime Interface (CRI) для Docker,
выступающий в роли моста между Kubernetes и Docker. Он позволяет Kubernetes управлять контейнерами.
Найти самый свежий релиз cri-dockerd можно на странице релизов.
Перед загрузкой рекомендуется проверить актуальную архитектуру с помощью команды: uname -m. Например, для Orange Pi 5
покажет архитектуру aarch64 (вариант ARM64). Скачаем соответствующий релиз:
sudo wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.16/cri-dockerd-0.3.16.arm64.tgz
Распакуем архив, переместим исполняемый файл в папку /usr/local/bin/ и удалим архив и временную папку с распакованным:
sudo tar xvf cri-dockerd-0.3.16.arm64.tgz
sudo mv cri-dockerd/cri-dockerd /usr/local/bin/
sudo rm -rf cri-dockerd*
Создадим службу cri-dockerd в systemd. Для этого в папке /etc/systemd/system/ создадим файл cri-docker.service.
Он описывает службу cri-dockerd и определяет, как и когда она должна быть запущена. Создадим файл:
sudo nano /etc/systemd/system/cri-docker.service
Содержимое файла (см. тут),
но с поправкой на путь к cri-dockerd (у нас он не /usr/bin/cri-dockerd, а /usr/local/bin/cri-dockerd):
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
# ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd://
ExecStart=/usr/local/bin/cri-dockerd --container-runtime-endpoint fd://
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
Где:
- [Unit] — Описывает службу.
Description— Описание службы.Documentation— Ссылка на документацию.After— Указывает, что служба должна быть запущена после указанных служб.Wants— Указывает, что служба требует наличия указанных служб.Requires— Указывает зависимость от сокетаcri-docker.socket.
- [Service] — Конфигурация службы.
Type— Определяет тип службы.ExecStart— Указывает команду, которая будет запущена при старте службы.ExecReload— Указывает команду, которая будет запущена при перезагрузке службы.TimeoutSec— Устанавливает время ожидания завершения службы.RestartSec— Устанавливает время между перезапусками службы.Restart— Указывает, как ведет себя сервис в случае ошибки.always— перезапускать всегда.StartLimitBurst— Устанавливает количество попыток запуска службы.StartLimitInterval— Устанавливает интервал между попытками запуска службы.LimitNOFILE— Устанавливает максимальное количество открытых файлов.infinity— неограничено.LimitNPROC— Устанавливает максимальное количество процессов.LimitCORE— Устанавливает максимальный размер ядра.TasksMax— Устанавливает максимальное количество задач.Delegate— Указывает, что служба может делегировать свои привилегии.KillMode— Устанавливает режим завершения процесса.
- [Install] — Указывает, когда и как служба должна быть активирована.
WantedBy— Указывает, что служба должна быть активирована вместе с ёmulti-user.targetё.
Создадим конфигурацию сокета cri-docker.socket для службы cri-dockerd. Она определяет, как и где сервис будет
слушать входящие соединения и управлять доступом к нему. Создадим файл:
sudo nano /etc/systemd/system/cri-docker.socket
Содержимое файла (см. тут):
[Unit]
Description=CRI Docker Socket for the API
PartOf=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=docker
[Install]
WantedBy=sockets.target
Где:
- [Unit] — Описывает службу.
Description— Описание сокета.PartOf— Указывает, что этот сокет является частью службы cri-docker.service.
- [Socket] — Конфигурация сокета.
ListenStream— Указывает путь к сокету, который будет использоваться для связи.SocketMode— Устанавливает права доступа к сокету (0660 — чтение и запись для владельца и группы, чтение для остальных).SocketUser— Устанавливает владельца сокета.SocketGroup— Устанавливает группу, которой принадлежит сокет.
- [Install]: Указывает, когда и как сокет должен быть активирован.
WantedBy— Указывает, что сокет должен быть активирован вместе с sockets.target.- Этот файл гарантирует, что cri-dockerd будет слушать на указанном сокете .
Теперь перезагрузим службы, настроим их на автозапуск и запустим их:
sudo systemctl daemon-reload
sudo systemctl enable cri-docker.service
sudo systemctl enable --now cri-docker.socket
Проверим доступность сокета пользователем `:
sudo usermod -aG docker $USER
Проверим, что контейнерный рантайм cri-dockerd работает. Например, командой:
sudo crictl --runtime-endpoint unix:///var/run/cri-dockerd.sock version
Увидим что-то вроде:
Version: 0.1.0
RuntimeName: docker
RuntimeVersion: 27.4.1
RuntimeApiVersion: v1
Не забудьте, что cri-dockerd нужно настроить и запускать на каждом узле кластера.
Настройка балансировщика нагрузки
Для обеспечения высокой доступности и автоматического переключения узлов в случае сбоя используется keepalived.
Он используется для настройки виртуальных IP-адресов (VIP) и в качестве балансировки нагрузки. VIP будет перемещаться
между узлами в зависимости от их состояния и приоритетов. Это означает, что в любой момент времени только один узел
будет отвечать на запросы, направленные на VIP. Когда этот узел выходит из строя, резервный узел с наивысшим
приоритетом берет на себя VIP и начинает отвечать на запросы. Это достигается с помощью протокола VRRP (Virtual Router
Redundancy Protocol), который обеспечивает автоматическое переключение VIP между узлами.
На предыдущейм шаге мы уже установили keepalived и можно проверить его наличие:
dpkg -l | grep keepalived
Настройка keepalived осуществляется через файл конфигурации /etc/keepalived/keepalived.conf. Этот конфиг
настраивает мониторинг состояния API-сервера и переключения на резервный узел в случае сбоя основного узла. Создадим
файл конфигурации:
sudo nano /etc/keepalived/keepalived.conf
Пример конфигурации для мастер-узла opi5plus-1. Он будет называться --
Betelgeuse (звезда спектрального класса M, т.е. оранжевая звезда, так же как и апельсинка Orange Pi), и иметь
VIP 192.168.1.250 (поменяйте на свой). Так же надо указать пароль для аутентификации между узлами,
участвующими в VRRP (вместо ********) и чтобы узлы могли корректно взаимодействовать между собой этот пароль должен
быть одинаковым на всех узлах.
global_defs {
enable_script_security
script_user nobody
}
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 4
}
vrrp_instance ORANGENET {
state MASTER
interface enP4p65s0
virtual_router_id 5
priority 100
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass ********
}
virtual_ipaddress {
192.168.1.250/24
}
track_script {
check_apiserver
}
}
Вот что делает каждая часть конфигурации:
global_defs— Глобальные настройки.enable_script_security— Включает безопасность скриптов.script_user nobody— Указывает пользователя, от имени которого будут выполняться скрипты,noboby-- минимальные привилегии.
vrrp_script check_apiserver— Определяет скрипт для проверки состояния API-сервера.script "/etc/keepalived/check_apiserver.sh"— Указывает путь к скрипту.interval 4— Интервал выполнения скрипта в секундах.
vrrp_instance MilkyWay— Определяет экземпляр VRRP (Virtual Router Redundancy Protocol).state MASTER— Указывает, что этот узел находится в резервном состоянии.interface enP4p65s0— Указывает сетевой интерфейс (у насenP4p65s0).virtual_router_id 5— Идентификатор виртуального маршрутизатора (от 1 до 255)priority 100— Приоритет узла (чем выше значение, тем выше приоритет).advert_int 1— Интервал объявлений VRRP в секундах.nopreempt— Запрещает узлу с более высоким приоритетом вытеснять активный узел, даже если он становится доступным. Это означает, что текущий MASTER узел останется активным до тех пор, пока он работает корректно, и только в случае его сбоя резервный узел с более высоким приоритетом станет MASTER. Другое значенияpreempt(и это значение по умолчанию) указывает, что если узел с более высоким приоритетом становится доступным, то он вытеснит текущий активный MASTER-узел. Т.е. если узел с более высоким приоритетом восстанавливается, он автоматически снова станет MASTER.authentication— Настройки аутентификации.auth_type PASS— Тип аутентификации (пароль).auth_pass ********— Пароль для аутентификации.
virtual_ipaddress— Виртуальный IP-адрес, по которому будет доступны узлы кластера.192.168.1.250— Виртуальный IP-адрес, который будет использоваться.
track_script— Настройки отслеживания скрипта.check_apiserver— Указывает скрипт для проверки состояния.
Теперь создадим скрипт /etc/keepalived/check_apiserver.sh для проверки состояния API-сервера. Он будет проверять
доступность API-сервера Kubernetes:
sudo nano /etc/keepalived/check_apiserver.sh
Содержимое скрипта:
#!/bin/bash
# File: /etc/keepalived/check_apiserver.sh
# Задаем переменные: VIP-адрес API-сервера, порт и протокол
APISERVER_VIP=192.168.1.250
APISERVER_DEST_PORT=6443
PROTO=http
# Определение функции errorExit
errorExit() {
# $* — это специальная переменная в shell, которая представляет все позиционные параметры, переданные в скрипт.
# 1>&2 — это перенаправление стандартного вывода (file descriptor 1) в стандартный поток ошибок (file descriptor 2).
echo "*** $*" 1>&2
# "код завершения" 1.
exit 1
}
# Проверка доступности API-сервера на localhost
curl --silent --max-time 2 --insecure ${PROTO}://localhost:${APISERVER_DEST_PORT}/ -o /dev/null || errorExit "Error GET ${PROTO}://localhost:${APISERVER_DEST_PORT}/"
# Если в сетевом интерфейсе узла есть VIP-адрес, то проверяем доступность API-сервера по VIP-адресу
if ip ad | grep -q ${APISERVER_VIP}; then
curl --silent --max-time 2 --insecure ${PROTO}://${APISERVER_VIP}:${APISERVER_DEST_PORT}/ -o /dev/null || errorExit "Error GET ${PROTO}://${APISERVER_VIP}:${APISERVER_DEST_PORT}/"
fi
# Если все проверки прошли успешно, то "код завершения" 0
exit 0
keepalived будет отслеживать код завершения и если скрипт завершится с ненулевым кодом, он интерпретирует это
как сбой и инициирует переключение виртуального IP-адреса (VIP) на другой узел с более высоким приоритетом.
Надо сделать скрипт исполняемым, добавить keepalived в автозагрузку и запустить его:
sudo chmod +x /etc/keepalived/check_apiserver.sh
sudo systemctl enable keepalived
sudo systemctl start keepalived
Настраиваем балансировщик нагрузки HAProxy
Итак, keepalived обеспечивает высокую доступность, переключая VIP между узлами в случае сбоя. А HAProxy на каждом
узле распределяет входящий трафик между контейнерами. Настройка HAProxy осуществляется через файл конфигурации
/etc/haproxy/haproxy.cfg. Создадим его:
sudo nano /etc/haproxy/haproxy.cfg
Пример конфигурации для HAProxy (не забудьте поменять IP-адреса на свои):
# File: /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# Глобальные настройки
#---------------------------------------------------------------------
global
log /dev/log local0 # Логирование в /dev/log с использованием локального сокета 0
log /dev/log local1 notice # Логирование в /dev/log с использованием локального сокета 1 с уровнем notice
maxconn 4096 # Максимальное количество одновременных соединений
stats timeout 30s # Таймаут статистики
daemon # Запуск в режиме демона
# По умолчанию SSL-клиентские сертификаты, ключи и методы
# ca-base /etc/ssl/certs
# crt-base /etc/ssl/private
# See: https://ssl-config.mozilla.org/#server=haproxy&server-version=2.0.3&config=intermediate
# ssl-default-bind-ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384
# ssl-default-bind-ciphersuites TLS_AES_128_GCM_SHA256:TLS_AES_256_GCM_SHA384:TLS_CHACHA20_POLY1305_SHA256
# ssl-default-bind-options ssl-min-ver TLSv1.2 no-tls-tickets
#---------------------------------------------------------------------
# Настройки по умолчанию для всех секций 'listen' и 'backend'
# если они не указаны в их блоке
#---------------------------------------------------------------------
defaults
mode http # Режим работы по умолчанию - HTTP
log global # Использование глобальных настроек логирования
option httplog # Включение логирования HTTP-запросов
option dontlognull # Не логировать пустые запросы
option http-server-close # Закрытие соединений сервером
option forwardfor except 127.0.0.0/8 # Добавление заголовка X-Forwarded-For, кроме локальных адресов
option redispatch # Повторная отправка запросов на другой сервер при сбое
retries 1 # Количество попыток повторной отправки запроса
timeout http-request 10s # Таймаут ожидания HTTP-запроса
timeout queue 20s # Таймаут ожидания в очереди
timeout connect 5s # Таймаут установки соединения
timeout client 20s # Таймаут ожидания данных от клиента
timeout server 20s # Таймаут ожидания данных от сервера
timeout http-keep-alive 10s # Таймаут keep-alive соединения
timeout check 10s # Таймаут проверки состояния сервера
errorfile 400 /etc/haproxy/errors/400.http
errorfile 403 /etc/haproxy/errors/403.http
errorfile 408 /dev/null # ошибки предварительного подключения Chrome
errorfile 500 /etc/haproxy/errors/500.http
errorfile 502 /etc/haproxy/errors/502.http
errorfile 503 /etc/haproxy/errors/503.http
errorfile 504 /etc/haproxy/errors/504.http
#---------------------------------------------------------------------
# apiserver frontend, который проксирует запросы на узлы управляющей плоскости
#---------------------------------------------------------------------
frontend apiserver
bind *:8888 # Привязка к порту 8888 на всех интерфейсах
mode tcp # Режим работы - TCP
option tcplog # Включение логирования TCP-запросов
default_backend apiserver # Назначение backend по умолчанию
#---------------------------------------------------------------------
# балансировка round robin для apiserver
#---------------------------------------------------------------------
backend apiserver
option httpchk GET /healthz # Проверка состояния серверов с помощью HTTP-запроса GET /healthz
http-check expect status 200 # Ожидание статуса 200 OK в ответе на проверку
mode tcp # Режим работы - TCP
option ssl-hello-chk # Проверка SSL-соединения
balance roundrobin # Доступны методы балансировки:
# roundrobin — по кругу, каждый новый запрос будет отправлен на следующий сервер по списку.
# leastconn — выбирает сервер с наименьшим количеством соединений.
# source — сервер на основе хэша IP-адреса клиента (клиента обработает один и тот же сервер).
# random — случайный сервер.
# static-rr — статический round-robin, каждый сервер получает одинаковое количество запросов.
# first — первый сервер в списке.
# uri — выбор сервера на основе URI запроса (каждый URI обработает один и тот же сервер).
# url_param — аналогично uri, но выбор сервера на основе параметра URL запроса.
# Отстальные методы см. документацию:
# https://www.haproxy.com/documentation/haproxy-configuration-manual/latest/#4.2-balance
server opi5plus-1.local 192.168.1.XX2:6443 check # Сервер opi5plus-1 с проверкой состояния
server opi5plus-2.local 192.168.1.XX3:6443 check # Сервер opi5plus-2 с проверкой состояния
server opi5plus-3.local 192.168.1.XX4:6443 check # Сервер opi5plus-3 с проверкой состояния
Добаляем HAProxy в автозагрузку и запускаем его:
sudo systemctl enable haproxy
sudo service haproxy restart
Теперь балансировщик нагрузки HAProxy будет принимать запросы на порт 8888 и перенаправлять их на узлы кластера.
Доступность узлов контролируется через HTTP-запрос GET /healthz. Ожидается ответ со статусом 200. Если узел не
отвечает на запрос, он помечается как недоступный и исключается из балансировки. Когда узел восстанавливает работу,
он добавляется обратно в балансировку.
Инициализация кластера Kubernetes
Теперь можно инициализировать кластер Kubernetes. На одном из узлов выполним команду kubeadm init:
sudo kubeadm init
После выполнения команды, в консоли появится сообщение с инструкциями по добавлению узлов в кластер. Например:
I0103 22:44:18.678608 191305 version.go:256] remote version is much newer: v1.32.0; falling back to: stable-1.30
[init] Using Kubernetes version: v1.30.8
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local opi5plus-1] and IPs [10.96.0.1 192.168.1.XX2]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost opi5plus-1] and IPs [192.168.1.XX2 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost opi5plus-1] and IPs [192.168.1.XX2 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "super-admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests"
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 2.001988898s
[api-check] Waiting for a healthy API server. This can take up to 4m0s
[api-check] The API server is healthy after 11.508746165s
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node opi5plus-1 as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node opi5plus-1 as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: t0t422.og4cir4p5ss3fai5
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.XX2:6443 --token здесь-будет-токен-для-подключения-узла-к-кластеру \
--discovery-token-ca-cert-hash sha256:здесь-будет-хэш-сертификата-кластера
Конфигурационный файл kubectl (~/.kube/config) создается при инициализации кластера с помощью команды kubeadm init. Если каталог .kube не был создан, возможно, вы пропустили шаги, которые следуют после инициализации кластера. Чтобы создать каталог .kube и скопировать конфигурационный файл, выполните следующие команды:
Создайте каталог .kube в домашнем каталоге:
mkdir -p $HOME/.kube
Скопируйте конфигурационный файл admin.conf в каталог .kube:
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
Измените владельца файла конфигурации на текущего пользователя:
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Эти команды создадут каталог .kube и скопируют конфигурационный файл, чтобы kubectl мог использовать его для подключения к кластеру.
Проверим api-сервера:
kubectl get componentstatuses
И увидим что-то вроде:
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy ok
Добавление рабочих узлов в кластер
На узле который хотим добавить создадим файл конфигурации kubeadm-config.yaml. Его можно создавать в любом месте,
так как он будет не нужен после добавления узла в кластер. Я предпочитаю создавать его в домашнем каталоге, в папке
.config (эта папка обычно создается автоматически и в ней хранятся конфигурационные файлы для различных программ):
mkdir -p ~/.config
nano ~/.config/kubeadm-config.yaml
Пример конфигурации для добавления узла в кластер (поменяйте IP-адрес мастер-узла, токен и хэш сертификата на свои):
kind: JoinConfiguration
discovery:
bootstrapToken:
apiServerEndpoint: "192.168.1.XX2:6443" # IP (или VIP) и порт API-сервера (master-узла)
token: "сюда-вставить-токен-который-получили-при-инициализации-кластера"
caCertHashes:
- "sha256:сюда-вставить-хэш-сертификата-который-получили-при-инициализации-кластера"
nodeRegistration:
criSocket: "unix:///var/run/cri-dockerd.sock" # Путь к cri-dockerd сокету
Токен и хэш сертификата для добавления узла в кластер был выведен в консоль после инициализации кластера. Создать и посмотреть токен (на самом деле всю команду инициализации) можно на мастер-узле командой:
kubeadm token create --print-join-command
Токен действует 24 часа после выпуска. Все действующие токены можно посмотреть командой:
kubeadm token list
Примечательно, что команда каждый раз генерирует новый токен (хеш сертификата остается неизменным). Токен используется только для первоначального добавления узла в кластер и действует ограниченное время (24 часа). Поэтому, если узел не был добавлен в кластер в течение этого времени, необходимо получить новый токен.
Теперь добавим узел в кластер:
sudo kubeadm join --config ~/.config/kubeadm-config.yaml
Получим приблизительно следующий вывод:
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 1.005191806s
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
Если теперь на основном узле выполнить команду:
kubectl get nodes
То увидим, что узел добавлен в кластер:
NAME STATUS ROLES AGE VERSION
opi5plus-1 NotReady control-plane 17h v1.30.8
opi5plus-2 NotReady <none> 12m v1.30.8
Но на присоединенном узле эта команда не будет работать, и мы увидим приблизительно следующую ошибку:
...
...
E0104 18:14:56.016385 86048 memcache.go:265] couldn't get current server API group list: Get "http://localhost:8080/api?timeout=32s": dial tcp [::1]:8080: connect: connection refused
The connection to the server localhost:8080 was refused - did you specify the right host or port?
Это происходит потому, что конфигурационный файл kubectl не был скопирован на второй узел.
На новом, присоединенном узле, создадим каталог .kube в домашнем каталоге:
mkdir -p $HOME/.kube
А на мастер-узле скопируем конфигурационный файл kubectl на присоединенный узел (не забываем заменить [user] на
имя пользователя):
sudo scp /etc/kubernetes/admin.conf [user]@opi5plus-2:~/.kube/config
В процессе копирования потребуется ввести пароль пользователя. После этого на присоединенном узле тоже можно будет
выполнять команды kubectl и управлять кластером и его узлами.
Установка сетевого плагина
Список узлов kubectl get nodes показывает, что узлы не готовы к работе (NotReady). Это происходит потому, что
на узлах не установлен сетевой плагин и нет сетевого взаимодействия между ними.
В Kubernetes существует несколько популярных CNI-плагинов (CNI -- Container Network Interface), каждый из которых имеет свои особенности и предназначен для различных сценариев использования. Вот некоторые из них:
- Flannel -- Простое и легковесное решение для сетевой подсистемы Kubernetes. Использует VXLAN для создания оверлейной сети. Подходит для простых кластеров и небольших сетей.
- Calico -- Обеспечивает сетевую политику и безопасность на уровне сети. Поддерживает как оверлейные, так и не оверлейные сети. Подходит для кластеров с высокими требованиями к безопасности и масштабируемости.
- Weave -- Обеспечивает простую настройку сети и автоматическое обнаружение узлов. Поддерживает шифрование трафика между узлами. Подходит для кластеров, где требуется простота настройки и безопасность.
- Cilium -- Основан на eBPF и обеспечивает высокую производительность и безопасность. Поддерживает сетевые политики на уровне приложений. Подходит для кластеров с высокими требованиями к производительности и безопасности.
- Kube-Router -- Объединяет функции маршрутизации, балансировки нагрузки и сетевых политик. Использует BGP для маршрутизации. Подходит для кластеров, где требуется интеграция с существующей сетевой инфраструктурой.
Т.к. я планирую в будущем подключать узлы во "внешнем интернете" (узлы будут находиться в разных сетях) и узлы будут не только на ARM64 (Orange Pi 5 и Apple Silicon), но и armv7 (Raspberry Pi 3B) и amd64 (x86_64), то выбор пал на Calico.
Применим манифест сетевого плагина Calico на мастер-узле:
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
Изменения, внесенные в манифест, могут занять некоторое время для обновления состояния всех узлов, распространиться и вступить в силу.
Проверим состояния узлов:
kubectl get nodes
И увидим, что узлы готовы к работе:
NAME STATUS ROLES AGE VERSION
opi5plus-1 Ready control-plane 25h v1.30.8
opi5plus-2 Ready <none> 8h v1.30.8
Если вы заметили, то второй узел opi5plus-2 не имеет роли. Kubernetes позволяет назначать узлам роли: мастер
(control-plane) и рабочий (worker). На рабочих узлах запускаются поды, а мастер-узлы используются для управления.
Задать роль второму узлу (opi5plus-2) можно командой:
kubectl label node opi5plus-2 node-role.kubernetes.io/worker=worker
Теперь роли узлов будут выглядеть примерно так:
NAME STATUS ROLES AGE VERSION
opi5plus-1 Ready control-plane 25h v1.30.8
opi5plus-2 Ready worker 8h v1.30.8
По умолчанию, на мастер-узле (у нас это opi5plus-1) запрещено запускать поды не относящихся к управляющей плоскости.
Такое расточительство 😜 можно пресечь. Разрешить запуск подов на мастер-узле нужно удалив taint с мастер-узла.
taint — это метка, которая назначается узлу и указывает какие поды могут быть запущены на узле.
Удалить taint-метку с мастер-узла можно командой:
kubectl taint nodes opi5plus-1 node-role.kubernetes.io/control-plane:NoSchedule-
Теперь для проверки можно сделать по одному поду на каждом узле, и проверить сетевое взаимодействие между ними.
На мастер-узле opi5plus-1 создадим каталог для манифестов и манифест пода busybox-master:
mkdir -p ~/kuber
nano ~/kuber/busybox-master.yaml
Содержимое манифеста /kuber/busybox-master.yaml:
apiVersion: v1
kind: Pod
metadata:
name: busybox-master
spec:
nodeSelector:
kubernetes.io/hostname: opi5plus-1
containers:
- name: busybox
image: busybox
command: ["sleep", "3600"]
Запустим под busybox-master:
kubectl apply -f ~/kuber/busybox-master.yaml
Теперь создадим манифест пода busybox-worker для рабочего узла opi5plus-2:
nano ~/kuber/busybox-worker.yaml
Содержимое манифеста /kuber/busybox-worker.yaml:
apiVersion: v1
kind: Pod
metadata:
name: busybox-worker
spec:
nodeSelector:
kubernetes.io/hostname: opi5plus-2
containers:
- name: busybox
image: busybox
command: ["sleep", "3600"]
Запустим под busybox-worker:
kubectl apply -f ~/kuber/busybox-worker.yaml
Посмотрим состояние подов:
kubectl get pods -o wide
Увидим, что оба пода запущены и получили IP-адреса:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-master 1/1 Running 2 (10m ago) 2h 172.16.95.1 opi5plus-1 <none> <none>
busybox-worker 1/1 Running 0 35s 172.16.74.7 opi5plus-2 <none> <none>
Теперь проверим сетевое взаимодействие между подами. Например запустим ping с busybox-master на busybox-worker
(обратите внимание на IP-адреса подов из предыдущего вывода, у вас они могут отличаться):
kubectl exec -it busybox-master -- ping -c 4 172.16.74.7
Превращаем воркер-узел в мастер-узел
Удаляем сертификаты на бывшем воркере.
sudo rm -rf /etc/kubernetes/pki/*